

상품별 최저가 정보를 알려주는 다나와 사이트에서 내가 원하는 상품을 가격이 변동될 때마다 실시간으로 상품의 최저가 정보를 텔레그램 메신저로 확인할 수 있는 프로그램을 제작해 보겠습니다.
이 프로젝트에서 사이트의 정보를 가져오면서 주로 활용할 라이브러리는 requests와 beautifulsoup4 (bs4)입니다. 단계별로 코드를 작성하면서, 각 라이브러리가 어떻게 사용되는지 자세히 알아보겠습니다.
requests 모듈
requests는 파이썬에서 가장 널리 사용되고 있는 HTTP 라이브러리 중 하나로, HTTP 요청을 간단하게 읽기 쉽게 처리할 수 있습니다.
requests 모듈을 설치하려면, 터미널에 다음 명령어를 입력하세요:
pip install requests
설치가 완료되면, 다음과 같이 requests 모듈을 불러올 수 있습니다. 매번 requests를 입력하지 않기 위해, 모듈의 이름을 r로 간단하게 정의할 수 있습니다.
이제 다나와에서 가격 정보를 확인하고 싶은 상품의 URL을 지정하여, 해당 URL로 GET 요청을 보낸 뒤 응답받은 텍스트를 저장하고 출력해 보겠습니다.
import requests as r
url = '다나와 상품url'
response = r.get(url)
print(response)
HTTP요청 시 차단을 피하려면?

앞서 설명한 방법으로 다나와 사이트에 접속할 때, 몇 가지 문제가 발생할 수 있습니다. 프로그램이 실제 사람이 브라우저를 통해 접속하는 것이 아니기 때문에, 다나와 서비스에서 비정상적인 접속으로 인식하고 접속이 차단될 수 있습니다.
이러한 문제를 해결하기 위해서는, 프로그램이 실제 브라우저를 통해 접근하는 것처럼 보이도록 user-agent 정보를 설정해야 합니다.

현재 사용자의 브라우저 user-agent를 확인할 수 있는 사이트에 접속하여 복사합니다.(링크)
import requests as r
url = '다나와 상품url'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
response = r.get(url, headers=headers)
print(response)기존 코드에서 headers 딕셔너리를 추가하고 키(user-agent) 값과 , User-agent정보(value)를 입력합니다.(#3)
get메서드를 사용할 때 url 뿐만 아니라, headers값으로 user-agent정보를 포함하여 요청을 전송합니다.(#7)
일부 웹사이트는 비정상적인 요청을 차단하기 위해 쿠키를 이용합니다. 특히, 요청을 보낼 때마다 쿠키가 달라지는 경우, 사이트에서 비정상적인 접근으로 인식하고 차단할 수 있습니다. 이러한 문제를 해결하기 위해, 첫 번째 요청에서 받은 쿠키를 이후의 요청에서도 동일하게 사용하여 차단을 피할 수 있습니다.
import requests as r
url = '다나와 상품url'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
# 첫 번째 요청으로 쿠키를 가져옴
first_response = r.get(url, headers=headers)
cookies = first_response.cookies
# 두 번째 요청에서 쿠키를 사용하여 데이터 가져옴
product_response = r.get(url, headers=headers, cookies=cookies)
print(product_response)위 코드에서 first_response를 통해 첫 번째 요청을 보내고, 이 응답에서 쿠키를 가져와 cookies 변수에 저장합니다. 이후, 두 번째 요청부터는 get 메서드에 cookies 매개변수를 추가하여 동일한 쿠키를 사용함으로써, 차단 없이 안정적으로 데이터를 가져올 수 있습니다.
상품 정보 불러오기
페이지 파싱
마지막으로 get 메서드를 사용하여 requests 로 불러왔다면, 이제 bs4 패키지를 활용해 상품명과 최저가를 추출해 보겠습니다. 먼저, 코드 상단에 bs4 를 불러옵니다.
import bs4
이전에 작성한 코드에 이어서 Beaultifulsoup 을 사용하여 user-agent와 cookies를 이용하여 요청을 보낸 뒤, HTML 텍스트를 파싱 하기 위해 lxml을 사용하여 파싱 된 결과를 soup에 저장합니다.
product_response = r.get(url, headers=headers, cookies=cookies)
soup = bs4.BeautifulSoup(product_response.text, features='lxml')
상품 이름, 가격 출력하기
이제 가져온 웹페이지의 HTML에서 상품이름과 가격에 해당하는 클래스명을 찾아서 findAll함수를 사용하여 정보를 추출할 수 있습니다. soup.findAll을 사용하여 특정 영역의 클래스를 선택하여 가져올 수 있으며, 여기에서 사용된 클래스 이름에 대해서 자세히 알아보겠습니다. 아래는 그 예시입니다.
각각 상품이름과, 상품가격을 가져와 저장합니다.
product_name = soup.findAll(class_="title")
price_lines = soup.findAll(class_="prc_c")
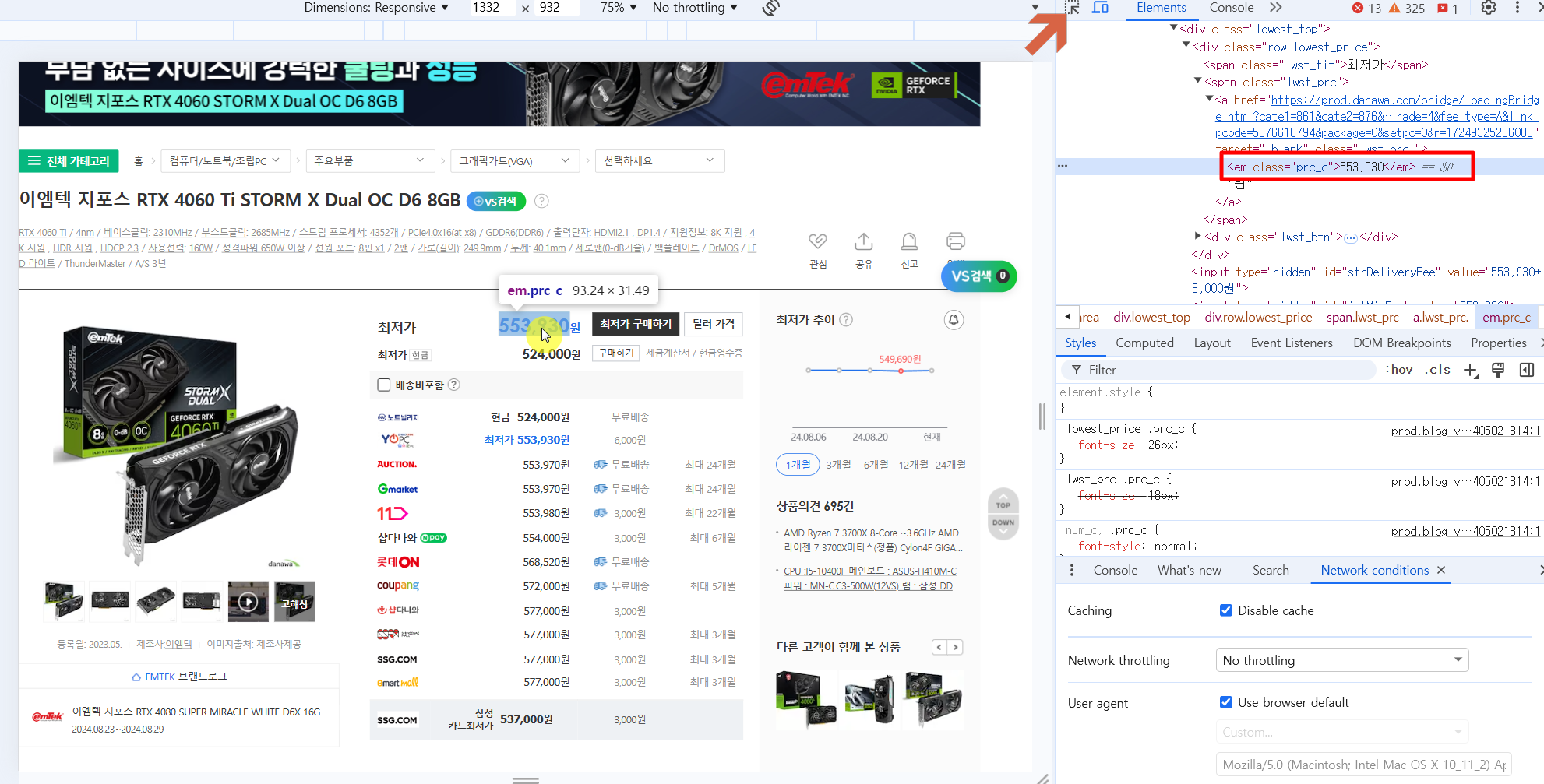
사용하는 브라우저의 개발자 도구(F12)를 실행시키면, 상품 가격에 해당하는 부분에 마우스를 가져다 대어 해당 HTML 소스를 확인할 수 있습니다. 예를 들어, 사진 속에서는 최저가 금액을 선택했으며, HTML에서는 클래스 이름이 'prc_c'로 지정되어 있습니다. 이와 마찬가지로, 상품 이름에 해당하는 부분도 선택 도구(사진 속 화살표로 표시된 부분)를 사용해 마우스로 선택하면, 해당 상품의 클래스명을 확인할 수 있습니다.
[<em class="prc_c">553,930</em>, <em class="prc_c">524,000</em>, <em class="prc_c">553,930</em>]
[<span class="title">이엠텍 지포스 RTX 4060 Ti STORM X Dual OC D6 8GB</span>, <dt class="title">공지
</dt>, <strong class="title">콘텐츠산업진흥법</strong>, <dt class="title">콘텐츠의 명칭</dt>, <dt class="title">콘텐츠의 제작 및 표시 연월일</dt>, <dt class="title">콘텐츠의 제작자</dt>, <dt class="title">콘텐츠의 이용조건</dt>, <strong class="title">다나와 고객센터</strong>]상품 가격과 상품이름을 출력해 보았더니, 필요한 텍스트 부분뿐만 아니라 HTML태그가 전체가 출력되는 걸 확인할 수 있습니다. 이런 경우, replace 함수를 사용하여 필요 없는 부분을 제거하고, 원하는 결과만 출력할 수 있습니다.
하지만 현재 데이터가 리스트 형태로 저장되어 있기 때문에 replace 함수를 직접 사용할 수는 없습니다. 이럴땐 for 문을 사용하여 리스트의 각 항목을 읽어 들인 뒤, 값을 변경하고, append를 사용해 새로운 리스트에 저장할 수 있습니다.
products = []
prices=[]
for price in price_lines:
result_price = price.text.replace('[<em class="prc_c">','')
result_price = price.text.replace('</em>, <em class="prc_c">524,000</em>, <em class="prc_c">553,930</em>]','')
prices.append(result_price)
for product in product_name:
result_product = product.text.replace('[<span class="title">','')
result_product = product.text.replace('</span>','')
products.append(result_product)HTML에서 필요 없는 문자열을 제거하고 새롭게 저장될 빈 리스트 product와 prices 리스트를 생성합니다.
파싱 한 정보를 for문으로 가져와서 필요 없는 html태그 부분을 제거하고 각각 리스트에 가격과 상품이름만 담기도록 저장합니다.
마지막으로 새로운 리스트에 담긴 첫 번째 요소값을 가져와서 출력합니다.
print(f'{products[0]} : {prices[0]}원')
이제 파이썬 코드를 실행할 때마다 특정 상품의 이름과 최신 가격정보가 출력됩니다.

여러 상품정보 출력하기
지금은 한 개의 상품만 출력하지만 여러 개의 상품을 출력하려면 어떻게 해야 할까요? 다행히, 사이트의 상품 가격과 상품 정보에 해당하는 클래스 구조는 동일하므로, 찾고자 하는 상품의 URL만 바꿔주면 여러 상품의 정보를 쉽게 구현할 수 있습니다.
상품의 url를 살펴보면 pcode= 뒤에 상품의 고유번호가 존재합니다. 이 부분을 변수로 지정하고 해당 변수에 상품별 코드를 담아두면 여러 상품의 정보를 불러올 수 있을 거 같습니다.

product_lnk 리스트에 각 상품별 코드를 리스트 형태로 저장한 후, for문을 사용해 product_lnk 리스트를 순회하며 기존의 url 변수에 상품별 코드에 따른 URL이 완성되도록 할 수 있습니다. 이를 위해, 다나와 URL 기본 주소 뒤에 product_lnk에 있는 상품 코드를 합쳐서 완전한 상품 URL을 생성할 수 있습니다.
product_lnk =['32861312','33421820','40580420','32494520','13512254']
for product_lnk in product_lnk:
url = f'https://prod.danawa.com/info/?pcode={product_lnk}'
#...기존코드

코드를 실행해 보면 product_lnk에 담긴 상품별 정보가 출력되는 걸 확인할 수 있습니다.
텔레그램으로 실시간 가격정보 받기
파이썬에서 처리하는 데이터를 텔레그램으로 전송하는 내용은 이전에 상영영화 정보를 조회하는 봇을 만들 때 사용했던 방법과 유사합니다.(링크)
모듈 설치
텔레그램 봇과 연동하기 위해서 아래 명령을 터미널에 입력하여 설치합니다.
pip install python-telegram-bot
코드 상단에 아래와 같이 파이썬 모듈을 불러옵니다.
import telegram
from telegram.ext import Updater, CommandHandler
텔레그램 봇 토큰 발급받기
모듈을 불러온 뒤, 텔레그램 봇을 사용하기 위한 토큰을 추가해야 합니다. 아래와 같이 코드를 작성합니다.
bot= telegram.Bot(token='your token')
봇 토큰을 발급받는 방법은 이전에 포스팅한 내용과 동일하니 참고해 주세요.
파이썬 - 텔레그램 상영영화 조회 봇 만들기 [3] - 텔레그램 봇 만들기
파이썬 - 텔레그램 상영영화 조회 봇 만들기 [2] - 크롤링 내용 추가 파이썬 - 텔레그램 상영영화 조회 봇 만들기 [1] - 검색결과 크롤링 목차 1.개발을 위해 필요한 도구 2.검색결과 크롤링 3.github
newstroyblog.tistory.com
텔레그램 메시지 전송
메시지를 전송하기 위해서는 채팅을 보낼 사용자id 를 확인해야 합니다
'API TOKEN' 부분에 앞서 발급받은 봇토큰을 입력하여 브라우저에서 접속합니다.
https://api.telegram.org/bot'API TOKEN'/getUpdates

처음 API URL에 접속하면 아무런 결과가 나타나지 않을 수 있습니다. 이때는 텔레그램 대화방으로 돌아가, 생성한 봇에게 아무 메세지나 보낸뒤 페이지를 새로고침합니다.

새로고침을 하게되면, 대화 내역이 출력되고 id부분에 사용자 고유 id가 나타납니다.
bot변수 바로아래에 chat_id 변수를 새로 추가하고 앞서 얻은 고유 id를 넣습니다.
chat_id = 'your chat id'
텔레그램 대화방으로 메시지를 전송하기 위한 기본적인 코드는 아래와 같습니다. text 부분에 전송하고자 하는 내용을 작성해야 하므로, 이전에 print문에서 사용했던 값을 넣으면 됩니다.
bot.sendMessage(chat_id=chat_id,text='text')
# 사용 예:bot.sendMessage(chat_id=chat_id,text=f'{products[0]} : {prices[0]}원')
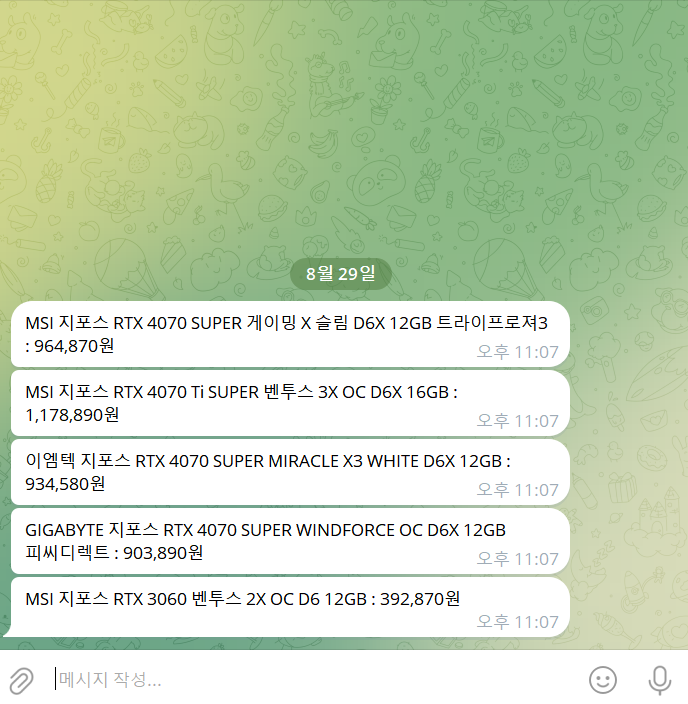
프로그램을 실행해 보면, 텔레그램 메신저로 원하는 정보가 정확히 전달되는 것을 확인할 수 있습니다.
텔레그램 메시지 오류 전송 시
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
print 로 출력할 때는 문제가 없지만, 텔레그램 봇으로 메시지를 전송하는 과정에서 경고문이 나타나면서 대화방에 메시지가 전송되지 않는 경우, asyncio를 통한 비동기 처리 방식으로 해결할 수 있습니다.
import asyncio
async def main():
기존 전체 코드
await bot.sendMessage(chat_id=chat_id,text=f'{products[0]} : {prices[0]}원')
def job():
asyncio.run(main())asyncio 모듈을 불러온 뒤 async 를 사용한 함수로 전체 코드를 감싸준뒤 텔레그램 봇으로 메시지를 보내는 부분에 await으로 비동기처리를 사용하여 전송하도록 하면 오류가 없이 메시지가 전송됩니다.
실시간으로 가격 정보를 받아보려면?
이제 작성된 코드로 프로그램 실행시점에서의 정보를 올바르게 텔레그램 메신저로 받아올 수 있는데 이 정보를 주기적으로 받아오도록 해보겠습니다.
시간정보를 체크하기 위한 time과 스케줄단위로 프로그램을 주기적으로 실행시키기 위한 schedule을 불러옵니다.
schedule은 내장모듈이 아니기 때문에 pip install schedule 명령을 통해 설치하셔야 합니다.
import time
import schedule
이제 schedule을 사용하여 1분마다 전체 작업이 지속되게 할 수 있습니다.
1분이 너무 짧다고 생각하면 minutes대신에 hour로 변경하면 1시간마다 작동하게 됩니다.
schedule.every(1).minutes.do(job)
while True:
schedule.run_pending()
time.sleep(1)
깃허브 전체코드
GitHub - Blue-B/danawa_product_price: 다나와 상품검색 사이트 특정 상품들의 실시간 가격정보를 텔레그
다나와 상품검색 사이트 특정 상품들의 실시간 가격정보를 텔레그램으로 확인할 수 있습니다. Contribute to Blue-B/danawa_product_price development by creating an account on GitHub.
github.com