

파이썬 - 나만의 가상 친구, garadio로 AI 챗봇 웹앱 만들기 - 2 기능추가
파이썬 - 나만의 가상 친구, garadio로 AI 챗봇 웹앱 만들기 나만의 AI 만들기 소개 [Python] 나만의 음성 AI 일본인 친구 만들기 | github배포 .feat 치사토 미리보기녹화후 확인해보니 음성이 두개가 겹쳐
newstroyblog.tistory.com
지난번 AI챗봇 웹앱에서 입력한 텍스트에 따라서 특정 기능을 작동하여 여러방면에서 활용할 수 있도록 알아보았습니다.
이번에는 AI챗봇이 단순 텍스트 대화뿐만 아니라 음성까지 출력되도록 구현해보도록 하겠습니다.
모든 패키지 일괄설치

깃허브에 업로드된 파일에 함께있는 requirements파일을 통해서 프로젝트에 필요한 모든 패키지를 가상환경에 설치합니다.
pip install -r requirements.txt
이전 프로젝트 실행문제 발생시
기존에 작성한 프로젝트 실행시 'AttributeError: 'Textbox' object has no attribute 'style'. Did you mean: 'scale'? ' 라는 오류가 발생한다면 gradio의 버전을 수정하여 해결할 수 있습니다.(참고링크)
Gitissues에서 제시된 문제해결 방법에 따라 gradio버전을 변경하면 됩니다.
pip uninstall gradio
pip install gradio==3.50.0
OpenAi Text to speech API
OpenAI에서 제공하는 Text to speech(링크)를 사용하면 다양한 음성 스타일로 텍스트를 음성으로 출력할 수 있습니다.
이 기능을 적용하여 AI의 음성을 출력하는 기능을 사용해보겠습니다.
음성 모델

API문서에서는 6가지의 음성 스타일을 제공한다고 나와 있으며 남성 4명, 여성2명의 목소리를 지원합니다.
한국어 지원

모델을 사용하여 텍스트를 읽고 음성으로 출력할때 다양한 언어를 지원하는데 그중 한국어도 지원하는걸 공식 문서를 통해서 확인할 수 있습니다.
파이썬 OpenAI TTS 음성 스트리밍
공식 문서의 음성 스트리밍 문제

Openai 문서에는 실시간으로 오디오를 스트리밍할 수 있는 코드를 제공하고 있습니다.
하지만 이 코드를 사용해보니 문제가 발생하였습니다.
from openai import OpenAI
client = OpenAI()
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Hello world! This is a streaming test.",
)
response.stream_to_file("output.mp3")일단 공식문서에서 제공하는 코드를 파이썬 3.12.1 버전에서 작성해보았습니다.
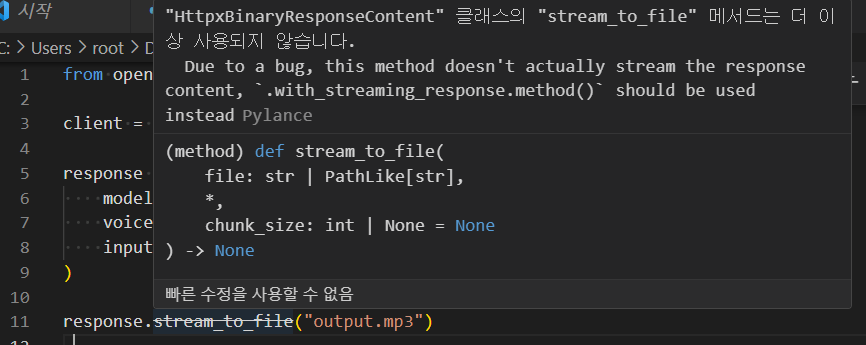
Due to a bug, this method doesn't actually stream the response content, `.with_streaming_response.method()` should be used instead
버그로 인하여 메서드가 응답 콘텐츠를 스트리밍하지 않으며 .with_streaming_response.method()를 사용해야 한다고 안내하지만 OpenAI의 문서에서는 이 내용을 찾아보기 어려웠습니다.
동일한 문제를 겪는 포럼 사례
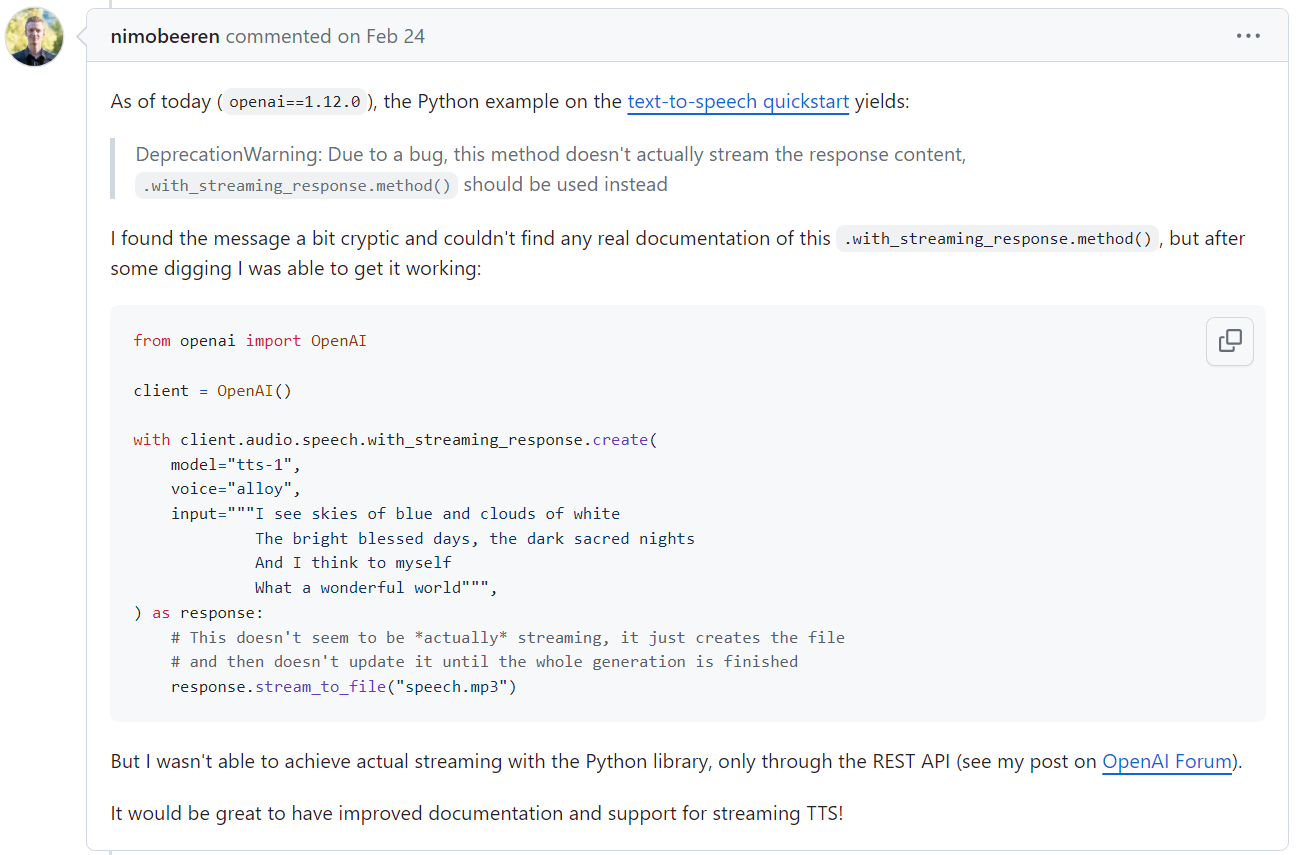
깃허브 이슈에서(이슈링크)동일한 문제를 겪는 내용을 찾아 볼 수 있었습니다
문제 해결대안 - pyaudio
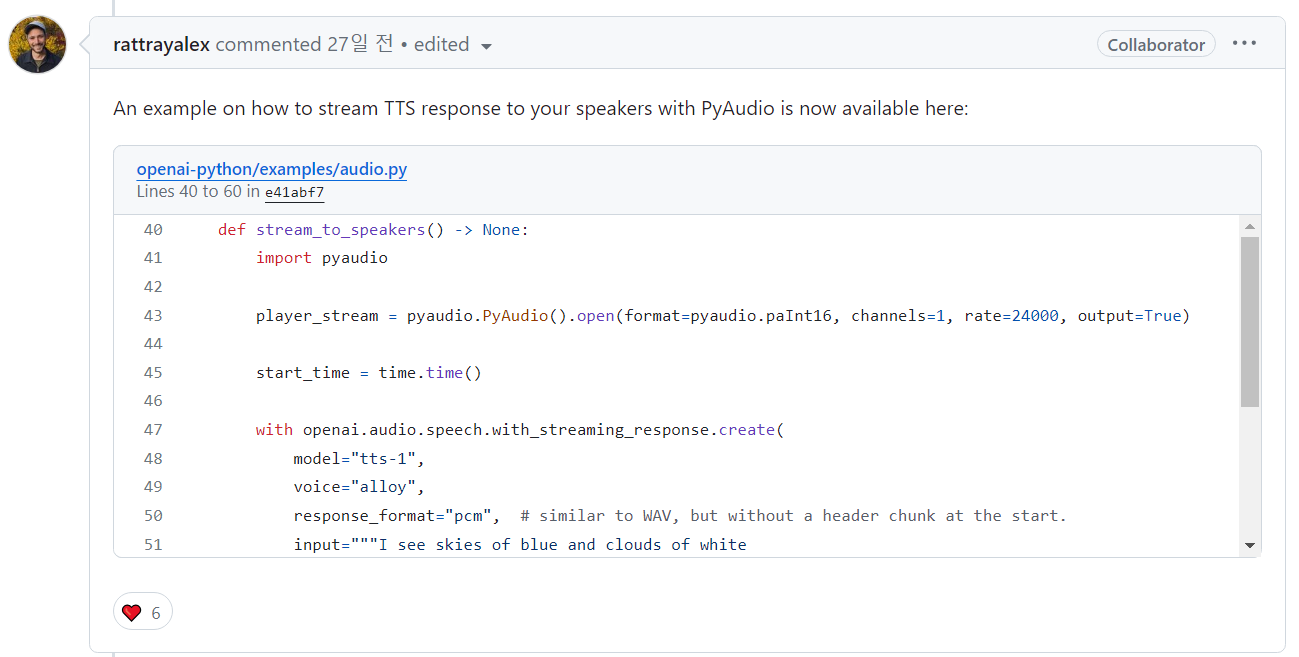
깃허브 이슈(이슈링크)에서 이를 대안하기위한 PyAudio를 통하여 TTS를 스트리밍하는 방법에 대한 글을 찾을수 있었습니다.
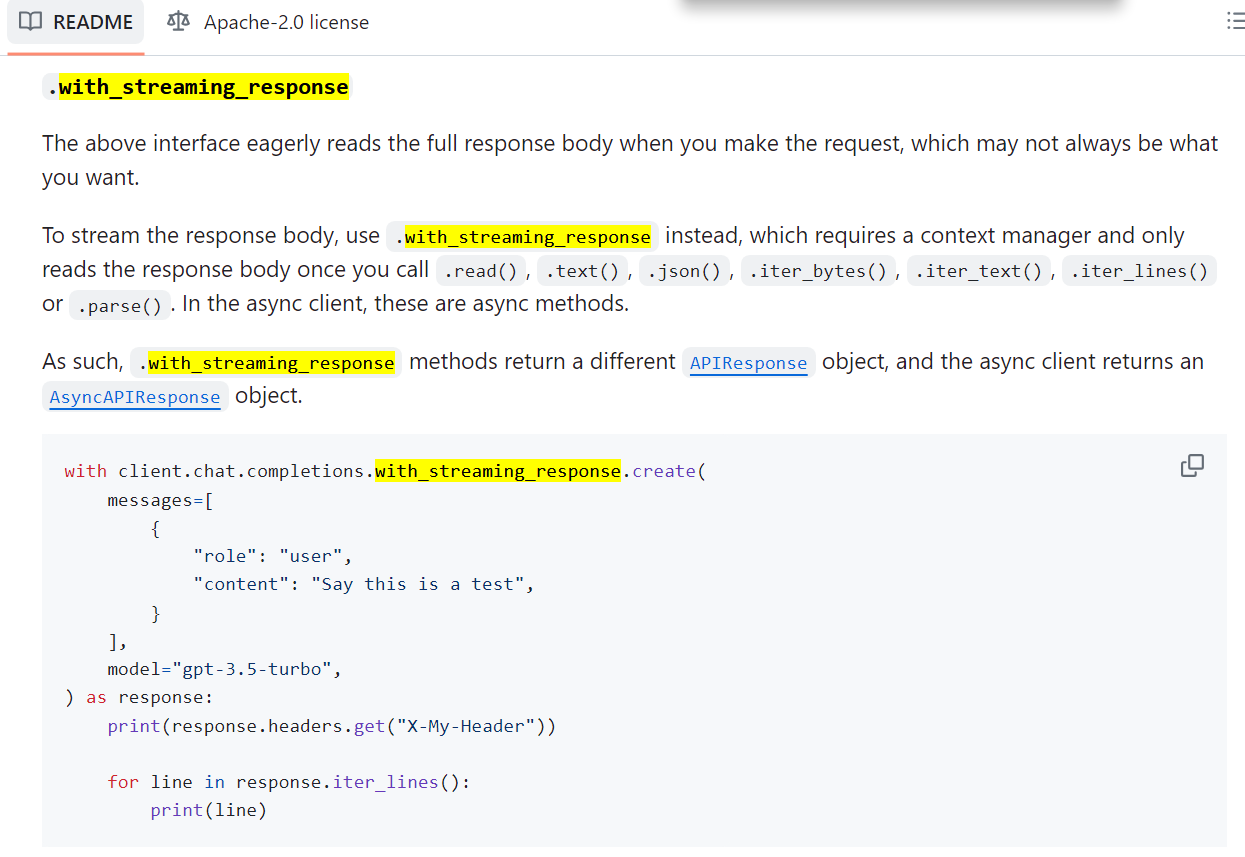
Openai 파이썬 깃허브 공식문서(링크)에서 제공하는 with_streaming_response을 호출하여 사용하면 해결됩니다.
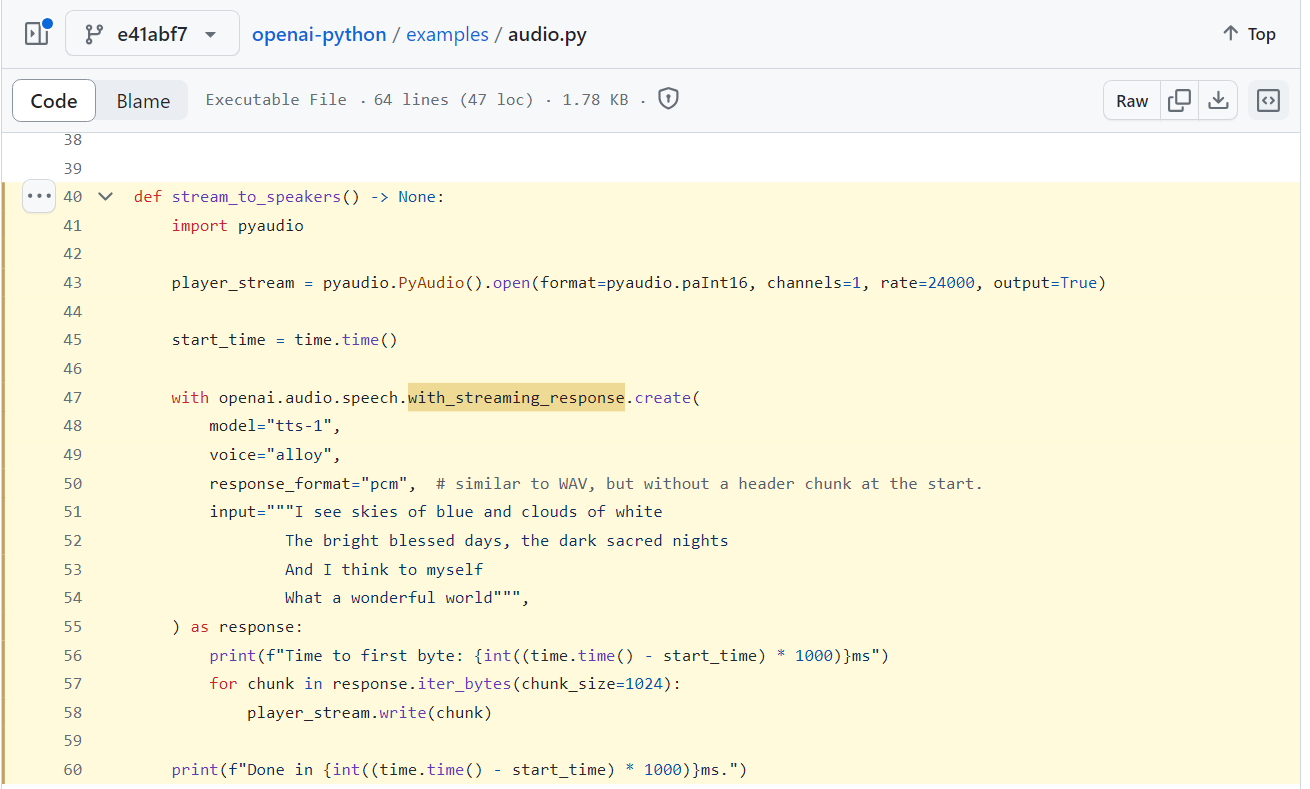
이에 대해서 바로 사용해볼 수 있도록 Openai 깃허브에서 examples로 제공하는 audio.py의 예제 코드를 참고하였습니다.(예제코드 링크)
파이썬에서 TTS음성 출력해보기
문서의 코드 내용을 실행해보고 문제를 해결하기위해서 찾는과정이 오래걸렸는데 그럼 이제 방금 말했던 openai 깃허브에서 제공하는 audio.py코드중 불필요한 부분은 제외하고 음성을 스트리밍하는 stream_to_speackers 함수부분을 가져와 파이썬에서 실행해보겠습니다.
import time
from pathlib import Path
from openai import OpenAI
# gets OPENAI_API_KEY from your environment variables
openai = OpenAI(api_key='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')
speech_file_path = Path(__file__).parent / "speech.mp3"
def stream_to_speakers() -> None:
import pyaudio
player_stream = pyaudio.PyAudio().open(format=pyaudio.paInt16, channels=1, rate=24000, output=True)
start_time = time.time()
with openai.audio.speech.with_streaming_response.create(
model="tts-1",
voice="alloy",
response_format="pcm", # similar to WAV, but without a header chunk at the start.
input="""I see skies of blue and clouds of white
The bright blessed days, the dark sacred nights
And I think to myself
What a wonderful world""",
) as response:
print(f"Time to first byte: {int((time.time() - start_time) * 1000)}ms")
for chunk in response.iter_bytes(chunk_size=1024):
player_stream.write(chunk)
print(f"Done in {int((time.time() - start_time) * 1000)}ms.")
stream_to_speakers()예제코드에서 불필요한 부분을 제외하고 stream_to_speakers()함수를 불러온뒤 바로 실행해보겠습니다. (예제코드 참조)
실행하면 input변수에 담겨진 텍스트가 음성으로 출력하게 됩니다.
음성의 모델을 바꾸려면 API문서(링크)에서 제공되는 음성모델( alloy, echo, fable, onyx, nova, shimmer)을 선택하여 voice='사용할 음성모델' 로 수정하면 됩니다. 음성모델은 전부 소문자로 입력해야 합니다.
with openai.audio.speech.with_streaming_response.create(
model="tts-1",
voice="nova",
response_format="pcm", # similar to WAV, but without a header chunk at the start.
input="""오늘 아침에 일어나서 창밖을 보니, 파란 하늘이 너무나도 맑게 느껴졌어요. 바람도 살랑살랑 불어오는 게, 마음까지 상쾌하게 만들어주더군요. 이런 날씨에는 산책이나 가볍게 운동을 하는 것도 좋을 것 같아요. 여러분은 오늘 어떤 계획을 가지고 계신가요?""",
)위 예시는 전체코드중 일부분으로 Nova라는 여성 음성목소리를 사용하여 텍스트를 재생할 수 있습니다.
파이썬 파일을 실행해보면 로컬환경에서 입력된 텍스트가 선택한 음성모델로 출력됩니다.
기존 프로젝트에서 AI응답 TTS로 출력하기
기존의 프로젝트 소스코드를 살펴보면 def chat_with_gpt(input, history): 함수에서 AI에게 사용자 입력을 보내고 응답을 받는 내용을 처리하였습니다.
AI응답 TTS 터미널에서 확인하기
# messages = [(history[i]["content"], history[i+1]["content"]) for i in range(1, len(history), 2)]
...
#ai응답 출력
if len(history) > 0 and history[-1]["role"] == "assistant":
print(f'ai응답: {history[-1]["content"]}')
...
# return messages, historychat_with_gpt 함수 코드부분의 하단 부분에 이렇게 작성해보면 AI의 응답을 받을때 터미널에도 메세지가 출력됩니다.
터미널에 메세지가 잘 출력되는걸 확인했으면 이제는 print로 터미널에 출력하는것이 아닌 AI의 응답을 stream_to_speakers함수의 input값으로 넘겨주어야 해당 함수에서 TTS를 재생합니다.
해당 부분의 코드는 TTS 함수를 작성한후 다시 작성할 예정이므로 위 코드는 확인이 끝났다면 삭제하도록합니다.
TTS 함수 작성하기
import time
from pathlib import Path
speech_file_path = Path(__file__).parent / "speech.mp3"
def stream_to_speakers(chat_response) -> None:
import pyaudio
player_stream = pyaudio.PyAudio().open(format=pyaudio.paInt16, channels=1, rate=24000, output=True)
start_time = time.time()
with client.audio.speech.with_streaming_response.create(
model="tts-1",
voice="nova",
response_format="pcm", # similar to WAV, but without a header chunk at the start.
input=chat_response,
) as response:
print(f"Time to first byte: {int((time.time() - start_time) * 1000)}ms")
for chunk in response.iter_bytes(chunk_size=1024):
player_stream.write(chunk)
print(f"Done in {int((time.time() - start_time) * 1000)}ms.")이제 chat_with_gpt함수위에 stream_to_speakers 함수를 작성합니다.
api 변수 지정
코드에서 기존과 다르게 11번째 줄에 with client.audio.~~ 부분에서 기존의 openai에서 client로 변경하였습니다.

client부분은 OpenAI api key를 담고있는 부분인데 이전 프로젝트에서 이부분을 client변수로 생성했기 때문에 변경하였습니다.
TTS 텍스트 지정
4번째 줄에 보면 stream_to_speakers함수에 chat_response라는 TTS로 재생할 AI의 응답 텍스트가 담긴 매개변수를 받도록 설정하였고 함수 내부에서는 15번째 줄에 input부분에서 넘겨받은 chat_response 변수를 지정합니다.
AI응답후 TTS재생하기
AI응답 TTS 터미널에서 확인하기부분에서 작성한 코드를 지운후에 작성한 TTS함수를 호출해보겠습니다.
#코드 최상단
import threding
...
#def chat_with_gpt(input, history):
# messages = [(history[i]["content"], history[i+1]["content"]) for i in range(1, len(history), 2)]
...
#ai응답 출력
if len(history) > 0 and history[-1]["role"] == "assistant":
threading.Thread(target=stream_to_speakers, args=(history[-1]["content"],)).start()
...
# return messages, historychat_with_gpt함수에서 사용자와 ai의 메세지를 meesage변수에 저장한뒤(2번째 줄) stream_to_speakers 함수를 호출하여 ai의 응답을 재생합니다.
if문을 통하여 history에 저장된 마지막 메세지가 assistant로 ai의 응답인경우 해당 메세지를 사용하여 stream_to_speakers함수를 별도의 스레드에서 실행하도록합니다.
11번째 줄에 함수 호출 부분은 Threading을 사용해 비동기 방식으로 처리했습니다. 일반적인 동기 방식에서는 TTS 음성 출력이 끝나야 값이 반환되므로, 웹상에서 사용자가 입력한 메세지에 대한 AI의 응답이 길 경우, 음성 출력이 완료될 때까지 화면에 대화가 표시되지 않습니다. 이를 개선하기 위해 비동기 방식을 적용하여, TTS 음성 출력과 동시에 화면에 대화 내용이 나타나도록 작성하였습니다.
Threading 함수를 사용하기위해서는 2번째 줄처럼 threading을 import해야합니다.
AI응답에 취소선이 출력되는 문제


stream_to_speakers함수를 호출하는 코드를 추가한 이후부터 ai의 응답에 취소선이 함께 출력되는 경우가 있었습니다.
해당 함수 응답에 직접적인 영향은 끼치지않으므로 아마 다른 문제가 있을꺼라고 생각하지만 이를 해결하는 방법이 있습니다.(github issues)
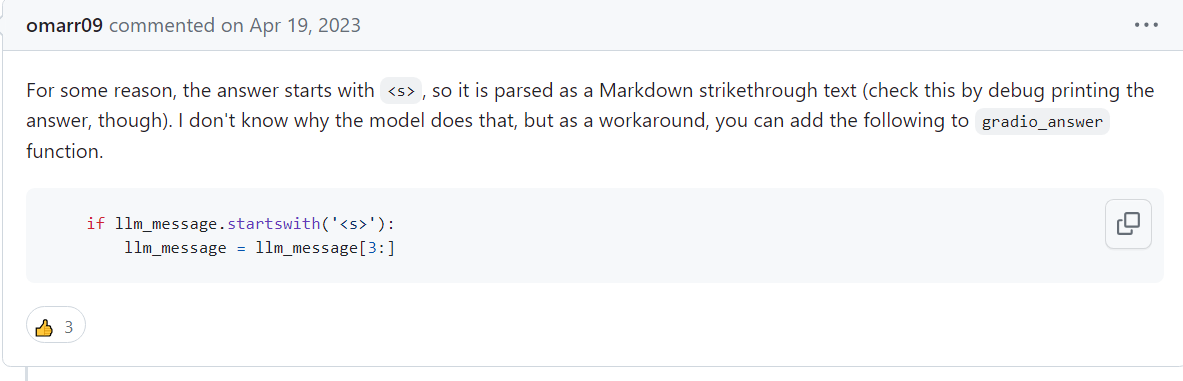
마크다운에서 <s>로 취소선 텍스트를 나타냅니다. 그래서 ai의 응답에서(llm_message) 문자열이 <s>태그로 시작할 경우, 이 태그를 제거하고 태그 이후의 문자열만 다시 저장합니다.
# response = gpt_response.choices[0].message.content
...
# 응답이 <s>로 시작하면 제거
if response.startswith('<s>'):
response = response[3:]
...
# history.append({"role": "assistant", "content": response})프로젝트 코드에서는 response함수에 ai의 응답을 받은뒤 if문으로 ai의 응답(response)에서 <s>태그로 시작할 경우, 제거후에 ai의 문자열만 저장하여 문제를 해결할 수 있습니다.
AI와 대화 시연영상
AI음성 출력
OpenAI에서 제공하는 한국어 음성모델이라 그런지 문장 구사력은 좋지만 지원되는 음성모델이 한정적이라는게 아쉬웠습니다. 하지만 이전의 단순 대화뿐만 아니라 음성기능까지 추가해보니 나중에 출력되는 음성을 변조하거나 더 나은 모델이 출시되면 사용해보는것도 좋을거 같습니다.
깃허브 링크
GitHub - Blue-B/gpt_friend
Contribute to Blue-B/gpt_friend development by creating an account on GitHub.
github.com