

이번에 파이썬 크롤링을 처음 공부하다가 프로젝트를 하나 만들어서 남겨두면
나중에 복습하는데도 도움이 되고 이해도 빠를 거 같아서 프로젝트를 진행하기로 하였습니다
개발을 위해 필요한 도구
크롤링을 진행하기 전에 파이썬 모듈도 설치해줘야 하는데
vscode의 하단 터미널 부분에 아래 모듈 세 개도 다운로드하여주세요
필요한 모듈
pip install requests
pip install beatufifulsoup4
pip install lxml
제가 크롤링할 사이트는 네이버 검색 결과 '메가박스 천안 상영시간표'입니다
메가박스 천안 상영시간표 : 네이버 통합검색
'메가박스 천안 상영시간표'의 네이버 통합검색 결과입니다.
search.naver.com
검색결과 크롤링 코드
import requests
from bs4 import BeautifulSoupvscode 상단에 위와 같이 작성하여 모듈을 불러옵니다
#네이버 검색결과 url주소를 url변수에 문자열로 저장
url = 'https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EB%A9%94%EA%B0%80%EB%B0%95%EC%8A%A4+%EC%B2%9C%EC%95%88+%EC%83%81%EC%98%81%EC%8B%9C%EA%B0%84%ED%91%9C'url변수에 크롤링할 url을 담습니다
#requests로 url의 정보를 불러온뒤 res변수에 저장
res = requests.get(url)
#서버로부터의 응답 문제가 있을경우 종료
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")이 부분까지는 기본적으로 크롤링 시에 필요한 부분이니 따라와 주시면 됩니다
그리고 이제 movie_list라는 변수를 새로 선언하여 영화 제목들을 크롤링해오려고 합니다
그전에 네이버 검색 결과의 html 코드가 어떻게 되어있는지 먼저 확인해봅시다

크롬 브라우저에서 메가박스 천안을 검색한 뒤에 키보드에 F12를 누르면 우측에 개발자 도구가 활성화됩니다

개발자도구 좌측 상단에 보면 이런 아이콘이 있는데 해당 아이콘을 누른 뒤에
검색 결과에 영화 제목 부분을 클릭하면 해당 코드가 위치한 곳을 자세히 보여줍니다

영화 제목을 클릭한뒤에 보면 이렇게 a태그로 영화 제목이 감싸 져 있는 걸 확인할 수 있습니다
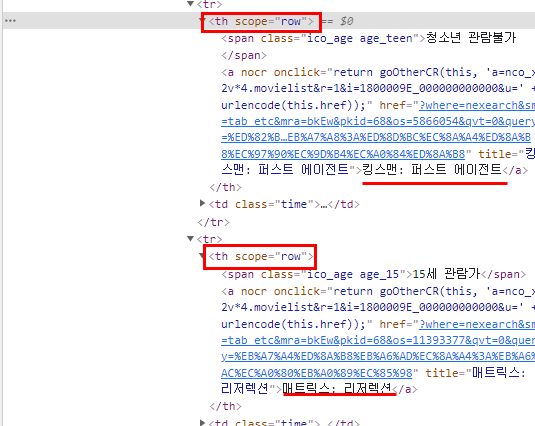
태그를 조금 자세히 살펴보면 그 아래에 있는 tr태그도 tr태그 아래에 자식 th가 있고 그아래에 영화 제목이 a태그로 감싸져 있습니다 즉 th태그 중에 scope가 row인 것들을 모두 찾아서 리스트에 담아서 한 줄씩 출력해주면 될 거 같습니다
movie_section = soup.find_all("th", attrs={"scope":"row"} )movie_section 변수를 새로 생성하고 이안에서 soup.find_all 명령으로 th태그 중에 scope가 row인 모든 요소를 반환해줍니다
find_all이 아닌 find함수를 사용할 경우 해당하는 첫 번째 값만 가져오게 됩니다

movie_sections변수를 print문에 담아 터미널에 출력해보니깐 위와 같이 긴 html태그가 나오는데 우리가 크롤링하고자 하는 영화 제목들이 포함되어있는 걸 확인할 수 있습니다
for movie_list in movie_section:
print(movie_list.a) #movie_list에 담긴 영화제목들중에서 a태그에 해당하는정보만 출력지금 이대로는 내용이 너무 많으니 for문을 사용하여 리스트 내용 중 영화 제목만 한 줄씩 해당하는 값을 출력해보겠습니다
find_all로 찾은 영화 제목들을 movie_list에 담아서 한 줄씩 출력하는데 영화 제목은 a태그로 감싸 져 있기 때문에 a태그에 해당하는 내용만 가져오겠습니다

그럼 이렇게 a태그의 내용 만들 만 출력이 되는데 다른 요소들도 포함되어있기 때문에 텍스트만 가져오려면 뒤에. get_text() 함수를 추가해주면 됩니다
for movie_list in movie_section:
print(movie_list.a.get_text())뒤에. get_text() 함수를 추가해준 뒤에 실행해보면

저희가 가져오고자 하는 영화 제목들만 가져올 수 있습니다
이후에 영화 제목뿐만 아니라 영화 시간들과 몇 관에서 상영하는지 등급은 어떻게 되는지도 추가해보려고 합니다
크롤링 과정 설명은 여기서 마치겠습니다
github 전체코드
GitHub - Blue-B/megabox-movie-list
Contribute to Blue-B/megabox-movie-list development by creating an account on GitHub.
github.com